Workspace setup
Load the Libraries we need.
Introduction
It’s Monday morning and I’ve got my coffee - time to get going for the week! This will be a quick post to share my project for the week - getting a Streamlit app up and running. More specifically, I’d like to spin up spaCy in an app with pre-loaded volumes (or articles?) from the Proceedings of the Academy of Natural Sciences of Philadelphia (ANSP). There is a demo version of this kind of Streamlit app that I can (and will) fork. I’ve already been wading around in the back-end of Streamlit, and it’s safe to say that while forking and adapting the demo app sounds simple, it’s at the edges of my Python comfort level (which is very basic). This is likely to be a slow process laden with muttered cuss words, but it will still be great fun. Here’s the plan:
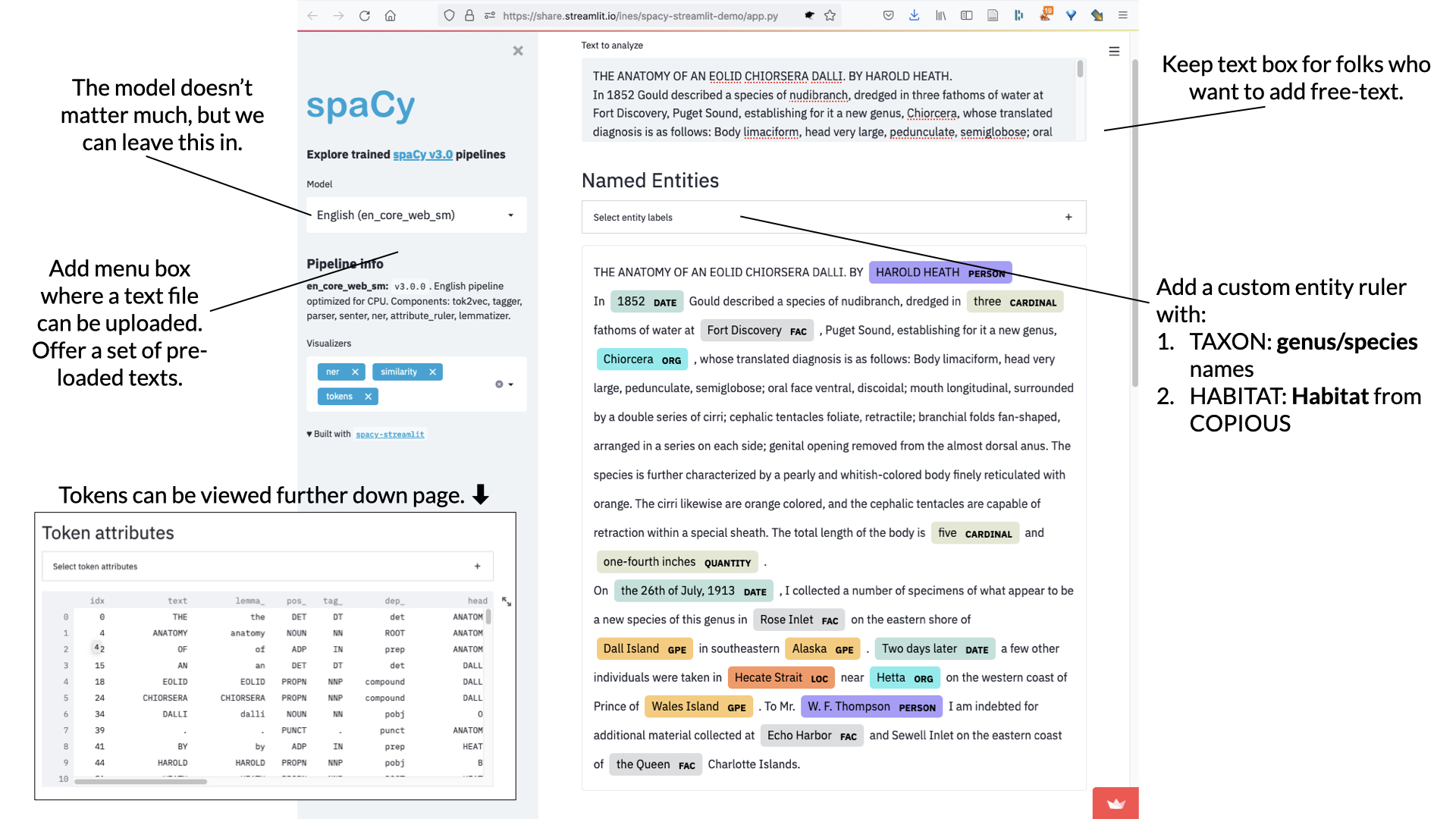
The general layout of the demo app is very close to what we want, which is FANTASTIC luck. You can see that we will have options to load texts (upload, copy/paste, or use provided set), the app will perform the spaCy natural language processing (NLP) pipeline, and visualize certain components. The named entity recognition (NER) results are shown as highlighted words. The default entities include things like people, geopolitical entities (countries, cities, states), dates, times, and so on. I’ll be adding two custom entity types in our app: taxonomic names that I’ve already identified in the corpus (see last post), and a set of habitats identified1 in texts from the Biodiversty Heritage Library.
Below the NER results, we can show the tokens2 from the NLP process. This is helpful and interesting because the current goal of my project is to identify species occurrences (“I saw this thing, at this place, on this day.”) in the corpus. To accomplish this, we have to get far beyond just finding genus and species names in the text - we need to train spaCy to find sentences that are good candidates for having taxa + location + date info. This is way harder! Understanding how spaCy “sees” the Proceedings will help us understand how the model is functioning.
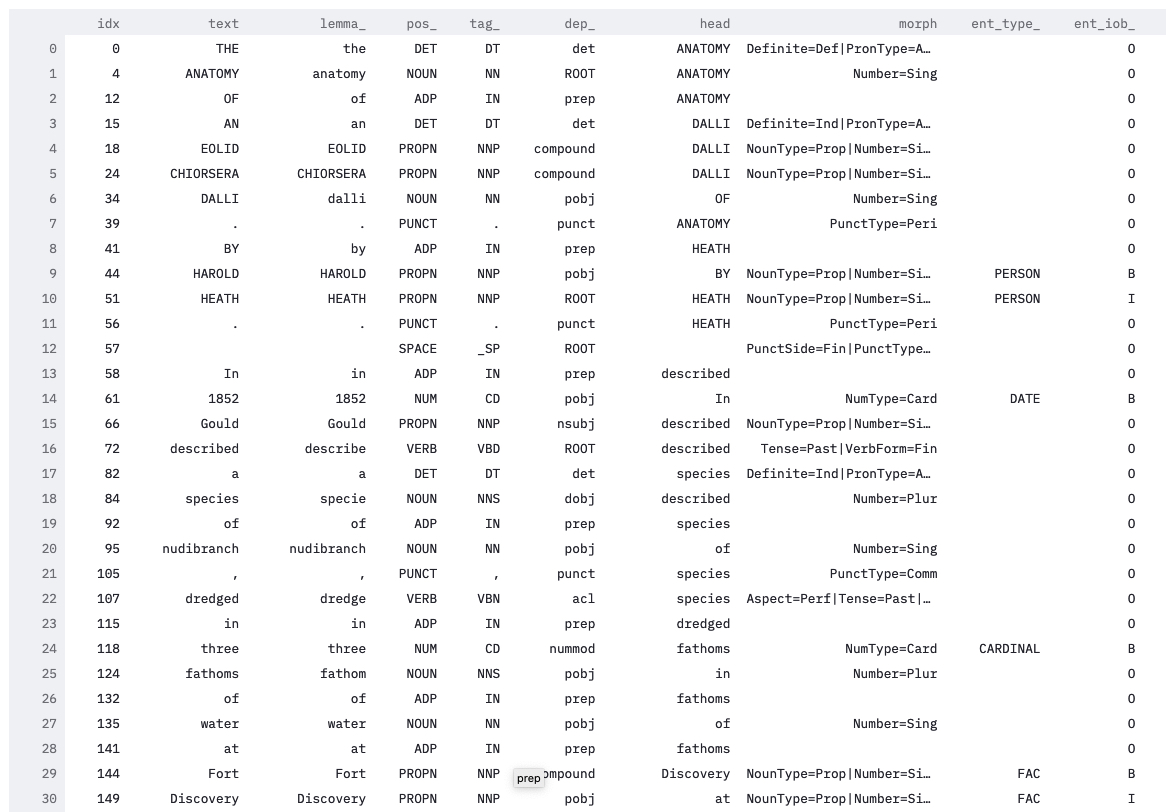
So, that’s what I’ll be up to this week …
from: Nguyen N, Gabud R, Ananiadou S (2019) COPIOUS: A gold standard corpus of named entities towards extracting species occurrence from biodiversity literature. Biodiversity Data Journal 7: e29626. https://doi.org/10.3897/BDJ.7.e29626↩︎
“Tokenization is the task of splitting a text into meaningful segments, called tokens.” spaCy↩︎