In my haste to get this blog and my fellowship project going, I never really took the time to describe what I’m going to be doing. I’ll do this now, in the briefest possible terms.
Fellowship Goal:
Correctly identify species occurrences (species + place + date) from the text of the Proceedings of the Academy of Natural Sciences of Philadelphia (ANSP; 1841-1922)
Why?
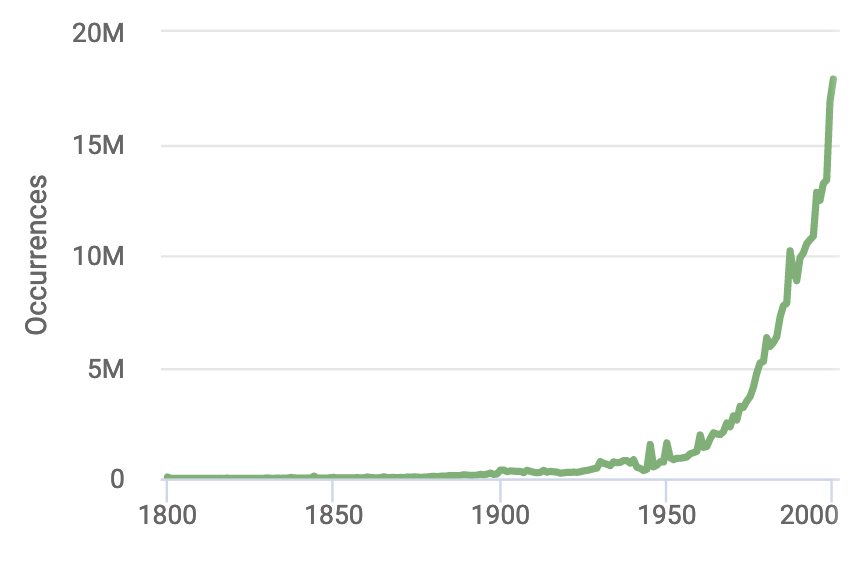
I am interested in how this corpus may be leveraged for historical species occurrence data so that I can contribute toward filling in the sparse occurrence data from this time period. Take a quick look at the data showing all species occurrence records from the Global Biodiversity Information Facility, GBIF, from 1800 - 2000. While the scale obscures the actual number of observations prior to 1950 (it’s not zero!), you get the gist of the problem of a lack of “old data.”
How?
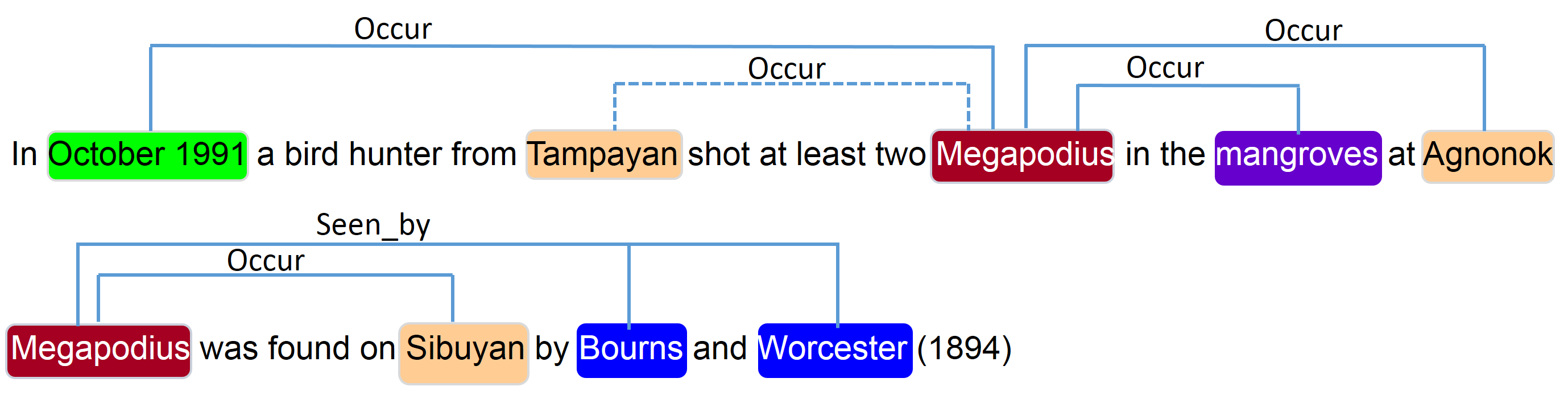
I don’t have it all figured out yet, but expect that this will involve many steps of data processing and cleaning, training a natural language processing model on this corpus (which is a weird corpus), exploratory data analysis and visualization, and more. If we can get it to work (and this is a big IF), we will be able to automate identifying realtionships like the one shown below.1 This example includes habitat, but we are focused on the relations between date + place + species.
To accomplish this, we are hoping to use the Python package spaCy. SpaCy is self-described as, “industrial-strength natural language processing in Python.” This powerful package does many things, but the two things it does that we really need are: named entity recognition (it finds words/phrases in the text, and we can give it a list of things to look for) and entity relations (we can train it to know when things are related, like a species and a place).
My first step in working toward this very lofty goal, was just to explore around in spaCy a bit. I did that, and you can see what I did in this Jupyter Notebook. The major successes for this first exercise were to:
- run the default spaCy NLP model on a volume of ANSP,
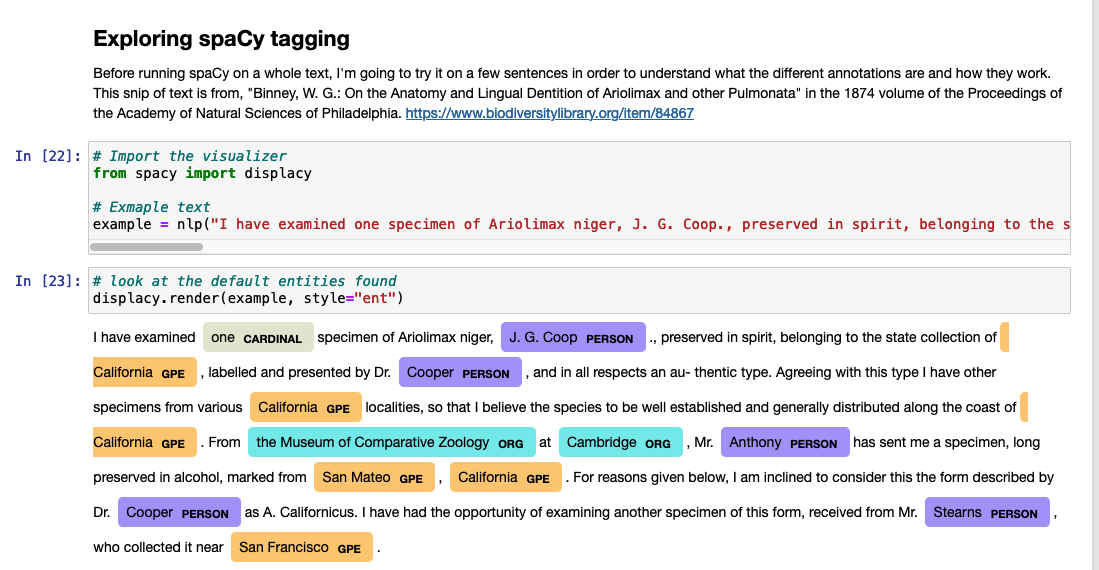
- to understand how to visualize some of the results:
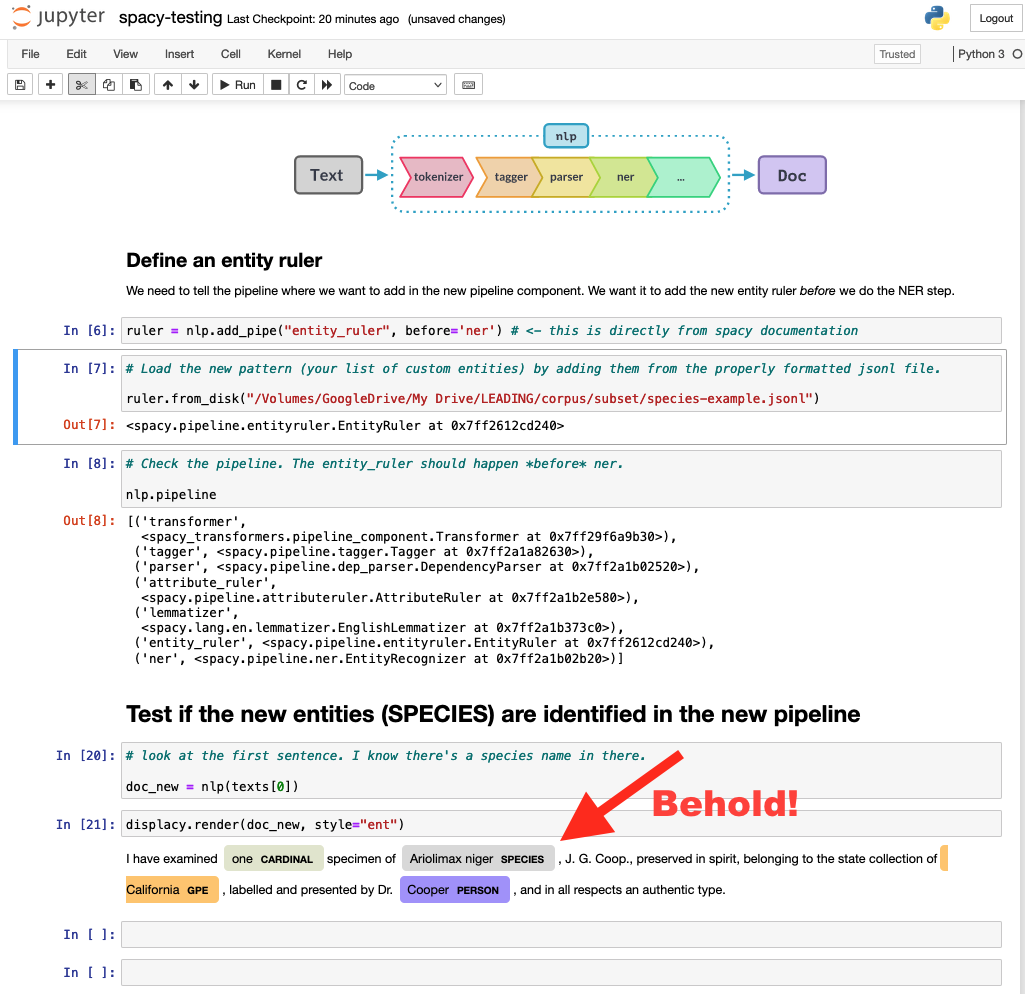
- and, finally, to create a custom entity set with a few species names, add it to the existing NLP pipeline, and see if it works.
It did!
All in all, this was a very exciting and productive week!
/a
from: Nguyen N, Gabud R, Ananiadou S (2019) COPIOUS: A gold standard corpus of named entities towards extracting species occurrence from biodiversity literature. Biodiversity Data Journal 7: e29626. https://doi.org/10.3897/BDJ.7.e29626↩︎